
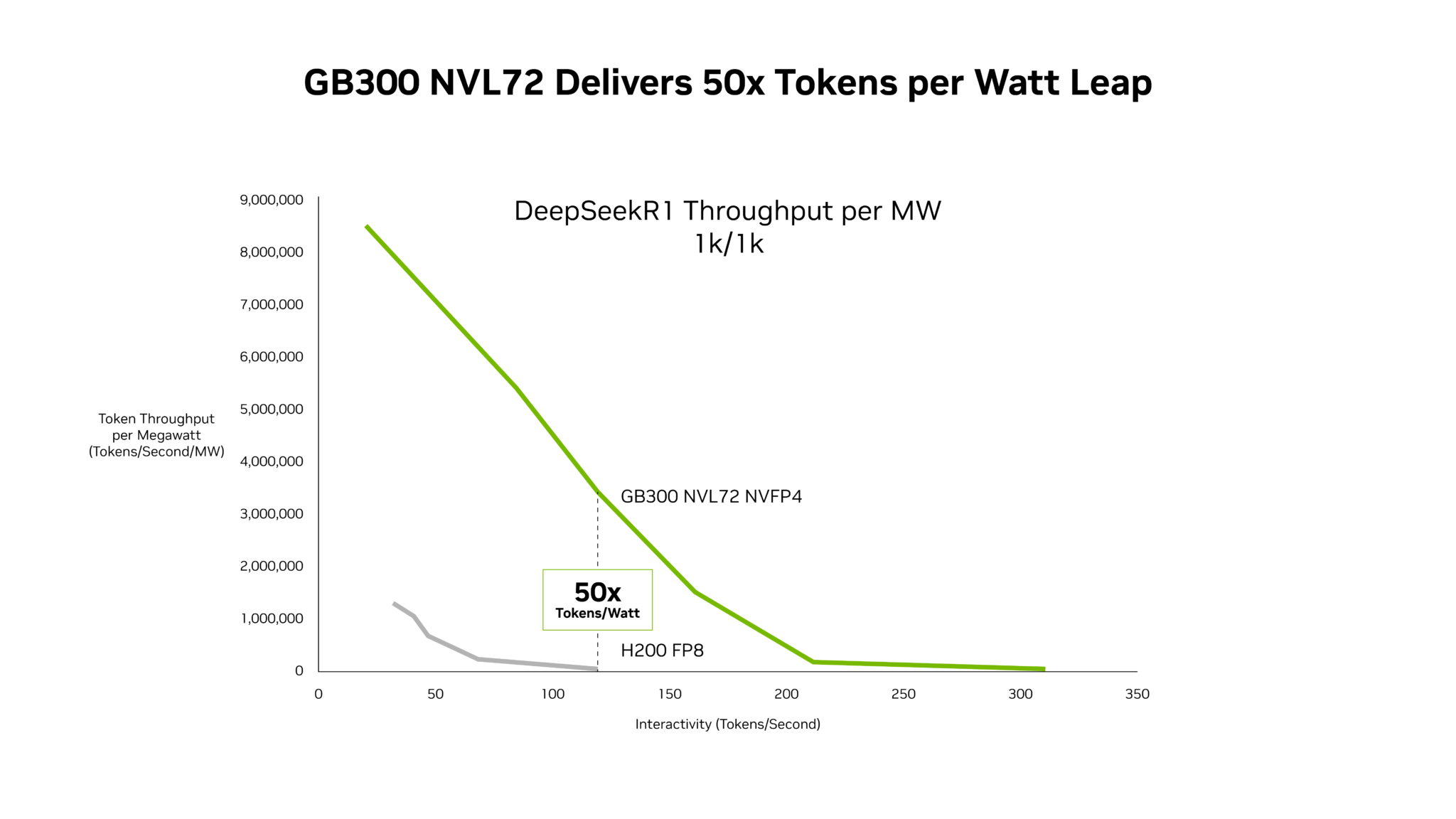
NVIDIA’s novel Blackwell Ultra platform is delivering up to 50 times higher throughput per megawatt and 35 times lower cost per token compared to its Hopper platform, according to new performance data from SemiAnalysis InferenceX. The gains are fueling adoption by leading AI inference providers, including Baseten, DeepInfra, Fireworks AI and Together AI, as demand surges for AI agents and coding assistants.
The shift towards AI agents is dramatically increasing the demand for AI processing power. OpenRouter’s State of Inference report indicates that software-programming-related AI queries have grown from 11% to approximately 50% of all queries in the past year. These applications require both low latency for real-time responsiveness and the ability to process large amounts of data – long context – when analyzing extensive codebases.
NVIDIA attributes the performance improvements to a combination of software optimizations and the Blackwell Ultra platform. Specifically, the GB300 NVL72 systems are at the forefront of these gains. Signal65 analysis shows the GB200 NVL72, with its hardware and software codesign, delivers more than ten times more tokens per watt than the Hopper platform, reducing the cost per token to one-tenth. Further optimizations from NVIDIA’s TensorRT-LLM, Dynamo, Mooncake, and SGLang teams are continually boosting throughput for mixture-of-experts (MoE) inference.
Key to the performance boost are several technical advancements. Higher-performance GPU kernels, optimized for efficiency and low latency, maximize Blackwell’s compute capabilities. NVIDIA NVLink Symmetric Memory enables direct GPU-to-GPU memory access, improving communication speed. Programmatic dependent launch minimizes idle time by overlapping kernel setup with previous kernel completion.
The GB300 NVL72, featuring the Blackwell Ultra GPU, achieves a 50x increase in throughput per megawatt compared to the Hopper platform. This translates to significant cost reductions, with NVIDIA GB300 lowering costs across the entire latency spectrum, and a 35x reduction in cost per million tokens for agentic applications. The combination of software optimization and next-generation hardware allows AI platforms to scale real-time interactive experiences to a larger user base.
For long-context workloads, the GB300 NVL72 offers additional advantages. In scenarios involving 128,000-token inputs and 8,000-token outputs – common in AI coding assistants analyzing codebases – the GB300 NVL72 delivers up to 1.5x lower cost per token compared to the GB200 NVL72. Blackwell Ultra’s 1.5x higher NVFP4 compute performance and 2x faster attention processing enable efficient understanding of entire codebases.
Several leading cloud providers and AI innovators have already begun deploying NVIDIA GB200 NVL72 at scale and are now transitioning to GB300 NVL72. Microsoft, CoreWeave, and OCI are among those deploying the new platform for low-latency and long-context applications like agentic coding and coding assistants. “As inference moves to the center of AI production, long-context performance and token efficiency become critical,” said Chen Goldberg, senior vice president of engineering at CoreWeave. “Grace Blackwell NVL72 addresses that challenge directly, and CoreWeave’s AI cloud, including CKS and SUNK, is designed to translate GB300 systems’ gains, building on the success of GB200, into predictable performance and cost efficiency. The result is better token economics and more usable inference for customers running workloads at scale.”
Looking ahead, NVIDIA is developing the Rubin platform, which combines six new chips into a single AI supercomputer. The company claims Rubin will deliver up to 10x higher throughput per megawatt compared to Blackwell, reducing the cost per million tokens to one-tenth. Rubin is also expected to reduce the number of GPUs needed to train large MoE models by 75% compared to Blackwell.