
AI-Assisted Systematic Reviews Gain Traction in Medical Research
A surge in studies evaluating large language models (LLMs) in clinical medicine is reshaping the landscape of systematic reviews, according to research published this month. Researchers have developed a new framework, PRISMA-DFLLM, combining the rigorous reporting standards of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines with the capabilities of domain-specific LLMs. The effort aims to accelerate and scale the process of evidence synthesis, whereas maintaining methodological integrity.
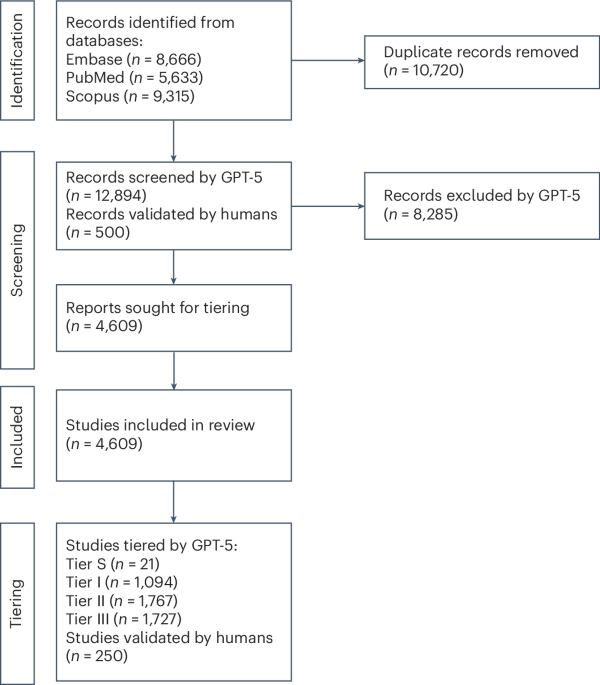
The study, conducted between January 1, 2022, and September 6, 2025, analyzed publications across PubMed, Embase, and Scopus. Researchers utilized specific search terms – including “large language model,” “LLM,” and names of prominent models like “GPT,” “ChatGPT,” “LLaMA,” “Claude,” “Gemini,” and “Bard” – to identify relevant research. The search focused on original research articles, conference papers, preprints, and letters related to human health, excluding reviews, meta-analyses, surveys, and commentaries.
To manage the volume of studies – ultimately totaling 4,609 included studies – researchers implemented an LLM-based screening pipeline using GPT-5. This AI was tasked with classifying studies based on whether they evaluated LLMs on clinical tasks or utilized them for non-clinical applications, such as literature summarization. A manual review of 500 randomly selected studies was conducted to validate the LLM’s performance, confirming its accuracy in identifying relevant research.
The research team also established a tiered system to categorize the quality of evidence presented in the studies. Tier S represents real-world, prospective evaluations of deployed systems in live clinical environments, while Tier I encompasses retrospective or prospective evaluations on real clinical data. Tier II includes studies utilizing simulated clinical situations, and Tier III covers evaluations based on board exams or multiple-choice questions. The LLM was used to assign studies to these tiers, with human validation performed on a subset of 250 studies to ensure accuracy.
Validation of the LLM’s screening performance revealed strong agreement with human screeners. The study employed a Bayesian hierarchical Dirichlet-multinomial model to estimate the true counts of studies within each tier, accounting for potential misclassification errors. Results indicate a growing trend in LLM-based medical research, with the rate of published studies increasing across all tiers.
Further analysis revealed that LLMs outperformed humans in a significant proportion of the included studies. The proportion of studies reporting LLM outperformance increased year-over-year, suggesting continuous improvement in the capabilities of these models. The study also examined the relationship between LLM performance and the experience level of the human evaluators, finding variations in outperformance rates across different levels of expertise.
The researchers also extracted metadata from each included study, including the specific LLM models evaluated, the relevant medical specialties, the type of human evaluator, and the data sources used. This data was categorized and analyzed to provide a comprehensive overview of the current state of LLM research in clinical medicine. The PRISMA-trAIce checklist, developed to improve transparency in AI-assisted systematic reviews, provides a framework for reporting these details.
The findings underscore the increasing role of AI in accelerating and enhancing systematic reviews, a critical component of evidence-based medicine. The PRISMA-DFLLM framework and the PRISMA-trAIce checklist offer tools to ensure the rigor and transparency of these AI-assisted processes. The study’s authors have made their code and prompts available on a GitHub repository, facilitating further research and collaboration in this rapidly evolving field.