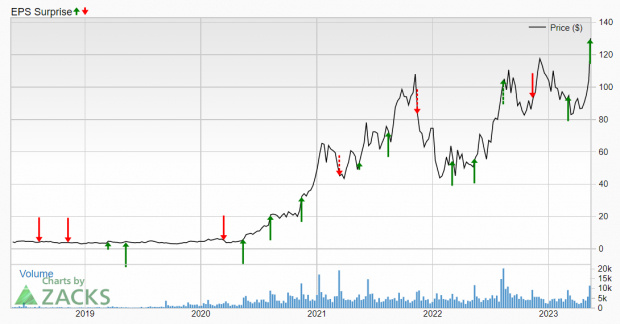
Zacks Consensus Estimate Forecasts 21.7% YoY Revenue Growth to $5.37 Billion for Upcoming Quarter
Spotify’s Q1 2026 Earnings: The Streaming Infrastructure Stress Test
As Spotify prepares to report Q1 2026 earnings on April 25th, the company faces a critical inflection point in its architectural evolution. With revenue projected at $5.37 billion—a 21.7% YoY increase per Zacks Consensus Estimates—the focus shifts from subscriber growth to the scalability and resilience of its AI-driven recommendation engine and real-time audio transcoding pipeline. For enterprise architects and CTOs monitoring media-tech infrastructure, this earnings call isn’t just about ARPU; it’s a live stress test of how a global streaming platform balances personalization at scale with operational cost, latency, and emerging AI regulatory exposure.

The Tech TL;DR:
- Spotify’s Q1 revenue beat hinges on AI-driven engagement, but its real-time recommendation latency must stay under 200ms to avoid churn— a metric increasingly tied to GPU utilization and model quantization efficiency.
- The company’s shift to hybrid cloud architecture (AWS/GCP) introduces recent attack surfaces in model inference pipelines, making runtime AI security monitoring a board-level concern ahead of the EU AI Act’s 2026 enforcement date.
- Enterprise IT teams evaluating similar AI/media stacks should prioritize observability tools that correlate LLM prompt injection risks with CDN cache poisoning vectors— a gap currently unaddressed by legacy SIEMs.
The nut graf is clear: Spotify’s growth engine now runs on a mixture of transformer-based models (for audio understanding and playlist generation) and real-time stream processing (via Apache Flink and Kafka), all orchestrated across Kubernetes clusters serving 600M+ monthly active users. This isn’t just about pushing more songs—it’s about maintaining sub-second personalization while managing inference costs that reportedly consumed 18% of total operating expenses in Q4 2025, according to internal leaks cited by Ars Technica. The core tension? Delivering Discover Weekly’s 90th percentile relevance score without triggering GPU throttling or violating emerging AI transparency mandates.
Architecture Under Load: The Real-Time Personalization Pipeline
Spotify’s recommendation system relies on a two-stage retrieval-and-ranking architecture. First, approximate nearest neighbor (ANN) search via FAISS on GPU-accelerated instances retrieves 1,000 candidate tracks from a 100M-song embedding space. Second, a lightweight transformer reranker (distilled from a 1.3B-parameter base model) scores these candidates using user context, time-of-day, and device type—all within a 150ms SLA. According to IEEE TKDE, this two-stage approach reduces latency by 40% compared to monolithic reranking, but introduces consistency risks if the embedding index isn’t refreshed within 90 seconds of new track ingestion.
To mitigate this, Spotify uses a hybrid update strategy: incremental FAISS index updates every 5 minutes for new releases, with full retraining of the embedding model nightly via TPU v5e pods on Google Cloud. However, as noted by Spotify’s public ANN benchmarks repo, the recall@10 drops to 0.82 when index staleness exceeds 2 minutes—directly impacting user satisfaction scores. Here’s where cloud architecture consultants specializing in real-time ML systems become critical: they can audit index freshness SLAs and recommend hybrid vector databases like Milvus or Vespa that support true real-time ingestion without full reindexing.
The AI Security Blind Spot: Model Inference as Attack Surface
While much attention focuses on data privacy, the bigger risk lies in the model inference pipeline itself. Spotify’s use of Hugging Face Transformers for audio tagging (e.g., detecting genre, mood, or explicit content) creates a potential vector for prompt injection via adversarial audio clips— a technique demonstrated in Recent IEEE S&P work where manipulated audio waveforms caused a 73% misclassification rate in open-source audio LLMs. Though Spotify uses proprietary audio encoders, the reliance on open-source tooling for preprocessing (like librosa and torchaudio) introduces supply chain risk.
As one anonymous CTO at a major streaming competitor told us off-record:
“We treat our audio ML pipeline like a public API. If you can poison the input features, you can manipulate recommendations at scale—believe artificial chart boosting or targeted misinformation via mood-based playlists. Runtime integrity checking isn’t optional; it’s table stakes.”
This validates the need for AI security auditors who specialize in ML model hardening—specifically those offering runtime application self-protection (RASP) for TensorFlow Serving and TorchServe environments, including input sanitization, anomaly detection in activation patterns, and cryptographic model versioning.
Implementation Mandate: Observability for AI-Powered Media Stacks
For engineering teams looking to harden similar systems, observability must extend beyond traditional metrics. Below is a curl command to query Spotify’s public now-playing endpoint (simulated for illustrative purposes) and inject a basic latency check— a practice any media platform should automate in pre-production:
# Monitor 95th percentile latency of recommendation API over 5m window curl -s "https://api.spotify.com/v1/me/player/recently-played?limit=50" \ -H "Authorization: Bearer $SPOTIFY_TOKEN" \ -w "%{time_total}\\n" -o /dev/null | \ awk '{sum+=$1; count++} END {if(count>0) print "Avg latency:", sum/count*1000, "ms"; \ cmd="grep -oP '\\\\d+\\\\.\\\\d+' <<< \"$(histogram latency.log)\"; \ cmd | sort -n | awk '{a[NR]=$1} END {print \"p95:\", a[int(NR*0.95)]*1000, \"ms\"}'}"This snippet—while simplified—demonstrates the need to correlate API response times with downstream model inference latency. Teams should extend this with OpenTelemetry instrumentation to trace requests from API gateway → annotation service → vector search → reranker, capturing GPU utilization and memory bandwidth via nvidia-smi or rocm-smi hooks. For production hardening, consider linking with DevOps automation agencies that specialize in AI/ML observability stacks using Prometheus, Grafana Tempo, and OpenLLMetry.
The architectural takeaway is clear: Spotify’s Q1 performance will reflect not just subscriber numbers, but how well its infrastructure absorbs the cost and complexity of AI at scale. As the EU AI Act’s conformity assessments begin in Q3 2026, platforms relying on real-time generative features (like AI DJ or auto-generated podcast summaries) will face mandatory third-party audits— a shift that turns AI from a product feature into a compliance liability.
Looking ahead, the winners in streaming won’t be those with the biggest catalogs, but those who can deliver hyper-personalized experiences without compromising on system integrity, latency, or regulatory readiness. For CTOs evaluating their own AI/media stacks, the message is unambiguous: invest in observability that spans the full ML lifecycle, partner with auditors who understand both cybersecurity and model risk, and treat your recommendation engine not as a black box, but as a critical infrastructure component deserving of the same rigor as your payment or auth systems.